龙腾副业网整站采集-数据采集火车头提取网盘下载地址采集规则!

如需采集规则!需提供会员!
这是【火车头采集龙腾副业网的网盘采集规则】(用于采集文章图片到你站点)
如你站点运营的也是相同类型站点,就可配合这采集规则-火车头工具一起使用
支持以下参数【如果有其它疑问,请联系客服咨询】qq:691310337
可自动采集相对应的【文章标题 – 文章内容 – 文章图片】 – 网盘下载链接 !
批量采集发布到自己的网站 – 火车头批量采集后 – 可批量转存网盘资源 – 同步分享提取码 – 批量发布自己的下载链接!
转存工具:https://www.cxyxt.com/30813.html
当我们在采集目标网站 – 龙腾副业网 – 是不是发现【F12 – 鼠标右键 – ctrl+u】被禁止的?
这时候我们怎么办呢?方法很简单 – 我们只需要在他网址前面加上 view-source: 就行 注【http前面】
来到源码页后点击左上角的自动换行
第一步:获取文章翻页数 – 可以看到他是点击加载更多 – 只时候我们只需要用到一个抓包工具: Fidder
去获取他翻页的链接 – 在火车头里面把翻页参数填高一点即可! 当访问页面没有的情况,是抓区不到内容的,这个不用担心!
第二步:在源码页中找到他的 <span class=”slash“></span> 文章表格表头
网址采集规则:手动获取规则
提取规则:<span class=”slash“></span>(*)</span>(*)<span class=”text“><a href=”[参数]” title
拼接地址:[参数1]
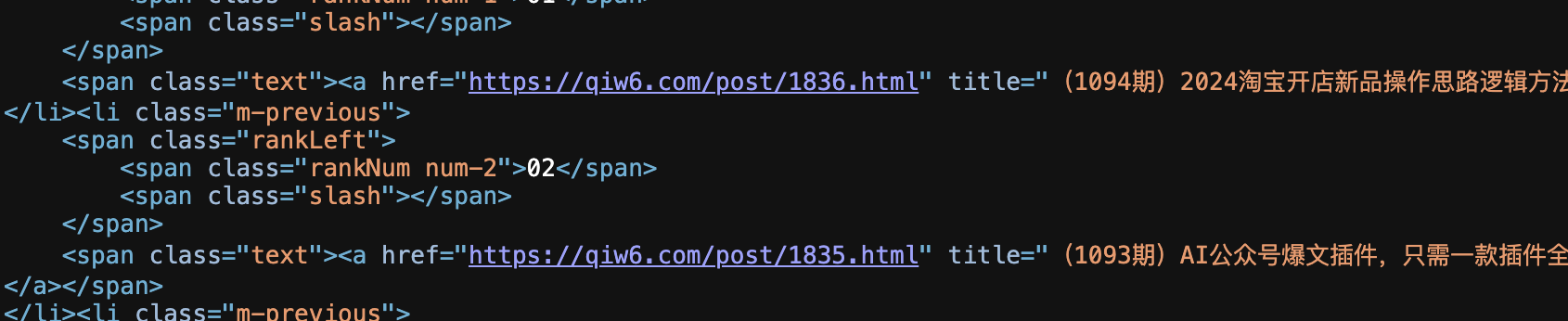
第三步:随便打开一篇文章进入源码页面 – 在网址前面加上 view-source: 就行 注【http前面】
内容采集规则:
标题:
一般在 <title>(1094期)2024淘宝开店新品操作思路逻辑方法(6节视频课) – 龙腾副业网</title> 和
<h1 class=”entry-title page-title“>(1094期)2024淘宝开店新品操作思路逻辑方法(6节视频课)</h1> 这两个位置获取标题
示例:正则提取
1 . 匹配内容:<title> [参数]</title>
组合结果:[参数1]
– 数据处理:内容替换排除:【 – 龙腾副业网】
2. 匹配内容:<h1 class=”entry-title page-title“> [参数]</h1>
组合结果:[参数1]
内容:
正则提取 – 匹配内容:<div class=”entry-content clearfix“> [参数]<div class=”lcphidebox lcp-bar lcphidebox-ani saletype1“>
组合结果:[参数1]
待补充……
免责声明:
本站所发布的一切资源仅限用于学习和研究目的;不得将上述内容用于商业或者非法用途,否则,一切后果请用户自负。本站信息来自网络,版权争议与本站无关。您必须在下载后的24个小时之内,从您的电脑中彻底删除上述内容。如果您喜欢该程序,请支持正版软件,购买注册,得到更好的正版服务。
附: 二○○二年一月一日《计算机软件保护条例》第十七条规定:为了学习和研究软件内含的设计思想和原理,通过安装、显示、传输或者存储软件等方式使用软件的,可以不经软件著作权人许可,不向其支付报酬!鉴于此,也希望大家按此说明研究软件!
注:本站所有资源均来自网络转载,版权归原作者和公司所有,如果有侵犯到您的权益,请第一时间联系邮箱:691310337@qq.com 我们将配合处理!联系QQ:691310337
----------------------------------------------------
版权声明: 一、本站致力于为软件爱好者提供国内外软件开发技术和软件共享,着力为用户提供优资资源。 二、本站提供的所有下载文件均为网络共享资源,请于下载后的24小时内删除。如需体验更多乐趣,还请支持正版。 三、我站提供用户下载的所有内容均转自互联网。如有内容侵犯您的版权或其他利益的,请编辑邮件并加以说明发送到站长邮箱(691310337@qq.com)联系QQ:691310337 站长会进行审查之后,情况属实的会在三个工作日内为您删除。
------------------------------------------------
创心域技术网:www.cxyxt.com(请添加到浏览器收藏夹)
----------------------------------------------------
版权声明: 一、本站致力于为软件爱好者提供国内外软件开发技术和软件共享,着力为用户提供优资资源。 二、本站提供的所有下载文件均为网络共享资源,请于下载后的24小时内删除。如需体验更多乐趣,还请支持正版。 三、我站提供用户下载的所有内容均转自互联网。如有内容侵犯您的版权或其他利益的,请编辑邮件并加以说明发送到站长邮箱(691310337@qq.com)联系QQ:691310337 站长会进行审查之后,情况属实的会在三个工作日内为您删除。
------------------------------------------------
创心域技术网:www.cxyxt.com(请添加到浏览器收藏夹)